


AI vs. Humans: A Noise Audit in Decision-Making
How Large Language Models exhibit lower levels of noise compared to human decision makers.


TL;DR
This article describes a study of noise audit in business decision making conducted with GPT-3.5-turbo and GPT-4 and with 52 human subjects. The results show that noise in LLMs is low, although it tends to increase with "temperature" (a setting in LLM API). It's also shown that decision noise is noticeably higher in the human results, which shows that LLMs can be applicable for business decision-making.
Research Overview
I conducted this research together with Professor Virginia Cha of the National University of Singapore (NUS) - a well known expert in innovation and business decision making.
We wanted to find out if LLMs are susceptible to decision noise, and we compared them to 52 human participants in the EMBA program.
I've already published several articles on the topic of decision noise - the latest one is here. Here’s another wonderful article on HRB on the same topic.
In short, Noise, as described in the book "Noise: A Flaw in Human Judgment" by Daniel Kahneman, Olivier Sibony, and Cass R. Sunstein, refers to the unwanted variability in judgments that should be consistent in similar cases. In decision making, people often exhibit high levels of noise, leading to inconsistent judgments. Large language models, such as the GPT family of systems, are increasingly used for decision-making tasks. Therefore, it's important to understand the noise that these LLMs exhibit at different temperatures and using different models.

Experimental design
The experiment was designed to test the level of noise in decision making in GPT-3.5 and GPT-4 by conducting a noise audit. To do this, 20 business-related questions were created that covered four categories: Rating or Scoring Questions, Categorical Questions, Estimation Questions, and Decision Thresholds. The questions were related to a fictitious company (TechSolutions Inc.) that was described in enough detail to allow for guesswork.
LLMs were asked the questions five times for each individual combination of temperature and model, resulting in 2000 data points. Human participants who were unaware of the noise audit were asked the same questions via a Google form as a task. All non-numeric responses were removed from the data set.
As mentioned earlier, all questions were related to the fictitious company TechSolutions Inc. which was described in enough detail that one could make a guess at each question. You can find the description of the company below:
(Scroll down to Results Analysis to see the results)
TechSolutions Inc. is a mid-sized technology company specializing in software solutions for the healthcare sector. The company was founded in 2015 and has experienced significant growth over the years, currently generating $50 million in annual revenue. They have a diverse range of products and services, including electronic health record (EHR) systems, telemedicine platforms, and healthcare data analytics tools.
In the past fiscal year, TechSolutions Inc. reported a 15% increase in revenue, amounting to $7.5 million, and a 12% increase in net profit, totaling $4.5 million. The company's current market share is at 20%, with three major competitors holding a combined market share of 70%. Their most recent product launch, the TeleHealth platform, resulted in a 10% increase in sales, bringing in an additional $5 million in revenue, and received 80% positive customer feedback.
TechSolutions Inc. has a workforce of 200 employees, with 60 employees working in research and development, 80 employees in sales and marketing, and the remaining 60 employees in administrative and support roles. The company provides regular training and development opportunities for its employees, with a focus on leadership and technical skills. The average tenure of employees at TechSolutions Inc. is 3.5 years, and the company has a 90% retention rate.
The company is considering several new projects for the next fiscal year, including an expansion into the European market, which is projected to generate an additional $10 million in annual revenue. They are also exploring the development of a new EHR system for small healthcare practices, aiming to capture 10% of this niche market, and a healthcare data analytics platform targeting insurance companies, which is forecasted to add another $8 million in revenue within two years. TechSolutions Inc. also plans to raise $15 million in additional funding to support these projects, either through equity investments or business loans.
The company's current cash reserves are at $10 million, with a long-term debt of $5 million at an average interest rate of 4%. TechSolutions Inc.'s gross profit margin is 60%, and its operating margin is 30%. The company has an annual R&D budget of $3 million, a marketing budget of $4 million, and allocates 10% of its revenue to employee training and development.
Then 20 questions were created - 5 in each of the categories. Here’s a list of categories and questions that were used for this test:
Rating or Scoring Questions
Considering TechSolutions Inc.'s financial performance, market presence, and employee development initiatives, rate the company's overall attractiveness as an investment opportunity on a scale of 1 to 10.
On a scale of 1 to 10, how would you rate TechSolutions Inc.'s overall performance in the past fiscal year, considering their revenue growth, net profit increase, and market share?
Considering the 10% increase in sales and 80% positive customer feedback, rate the success of the TeleHealth platform launch on a scale of 1 to 5.
Based on the company's employee training and development opportunities, rate the effectiveness of its talent development strategy on a scale of 1 to 10.
On a scale of 1 to 5, how well do you think TechSolutions Inc. is positioned to compete with the three major competitors in the healthcare software market?
Categorical Questions
Based on TechSolutions Inc.'s current financial situation and growth prospects, which of the following strategies should the company prioritize? Please choose one option: (1) Focus on organic growth through reinvesting profits (2) Pursue inorganic growth through mergers and acquisitions (3) Combine organic growth with selective mergers and acquisitions (4) Diversify into new markets while maintaining current growth strategies
Considering TechSolutions Inc.'s product portfolio and market presence, should the company primarily focus on (1) enhancing its existing products and services, or on (2) developing new and innovative solutions for the healthcare sector?
Given the company's current financial situation, should TechSolutions Inc. seek additional funding through (1) equity investments, (2) business loans, or (3) a combination of both?
Based on the company's growth strategy, should TechSolutions Inc. prioritize (1) expansion into the European market, (2) developing the new EHR system, or (3) creating the healthcare data analytics platform?
Considering the company's current employee structure, should TechSolutions Inc. (1) hire more employees in research and development, (2) sales and marketing, or (3) administrative and support roles?
Estimation Questions
Assuming TechSolutions Inc. successfully expands into the European market, estimate the percentage of total company revenue that will be generated from this new market within the first two years.
Given the TechSolutions Inc. 15% increase in revenue and 12% increase in net profit, estimate TechSolutions Inc.'s potential net profit growth in the next fiscal year (in percentage).
Considering the company's current market share of 20% and the competitors' combined market share of 70%, estimate TechSolutions Inc.'s potential market share in the next three years (in percentage).
Given the TechSolutions Inc. plans to raise additional funding, estimate the percentage of funds that should be allocated to the following project: Healthcare data analytics platform targeting insurance companies.
Based on the company's current workforce distribution (30% in R&D, 40% in sales and marketing, and 30% in administrative and support roles), estimate the percentage increase in the workforce required for sales and marketing department to support the company's growth over the next three years.
Decision Thresholds
TechSolutions Inc. is planning to expand its product line. What is the minimum projected annual revenue increase (in percentage) that would justify the development and launch of a new product in the healthcare software market?
TechSolutions Inc. is considering raising additional funding through business loans. At what annual interest rate (in percentage) would you recommend not pursuing this funding option?
TechSolutions Inc. is evaluating the potential return on investment (ROI) for the new EHR system project. What is the minimum ROI (in percentage) the company should expect to justify pursuing the project?
Assuming TechSolutions Inc. needs to raise $5 million to fund its expansion plans, what is the maximum percentage of company ownership that it should be willing to give up in exchange for the required funding, considering its current valuation of $25 million?
TechSolutions Inc. currently has a customer satisfaction rate of 85% for its products. In order to maintain its market position and strengthen customer loyalty, what should be the minimum percentage of positive customer feedback the company should aim for in the upcoming year?
After formulating the questions, I queried the OpenAI API to ask GPT-3.5-turbo and GPT-4 each of these questions along with the context and the various temperature settings from 0.0 to 1.0.
Each API call was context independent, i.e., LLM didn't know that other questions had been answered previously. Each question was asked in the following order:
messages=[
{"role": SYSTEM, "content": company_description},
{"role": SYSTEM, "content": "Your task is to give the best estimate of the answer the provided questions based on the given context to the best of your ability. You must only return an INTEGER number."},
{"role": USER, "content": question+"\\n\\n I NEED YOU TO PROVIDE A CONCISE ANSWER TO THE ABOVE QUESTION. RETURN ONLY MACHINE-READABLE ANSWER, NO EXPLANATION REQUIRED. ONLY A NUMER."}
]
(full code can be found in the resources section)
Results Analysis
Results were first adjusted for outliers using the interquartile range method with 1.5 IQR and then normalized to a range of 0 to 1 to allow comparisons between questions with different scales. Basically, we just made sure that the data were clean and comparable.
I created scatter plots and standard deviation plots for both the GPT-4 and the GPT-3.5 and for the human participants. These plots show that increasing the temperature for LLMs increases the standard deviation for some questions. There wasn't much difference between GPT-4 and GPT-3.5 in terms of deviation of responses at different temperatures, with a few exceptions for certain questions.

For several questions, both models showed complete agreement of answers and no noise, while for some other questions at least one of the systems showed a complete absence of noise. Only for a few questions did the LLMs show a relatively high level of noise as measured by the standard deviation of the responses.
For the human participants, however, the standard deviation of responses was much more spread out:
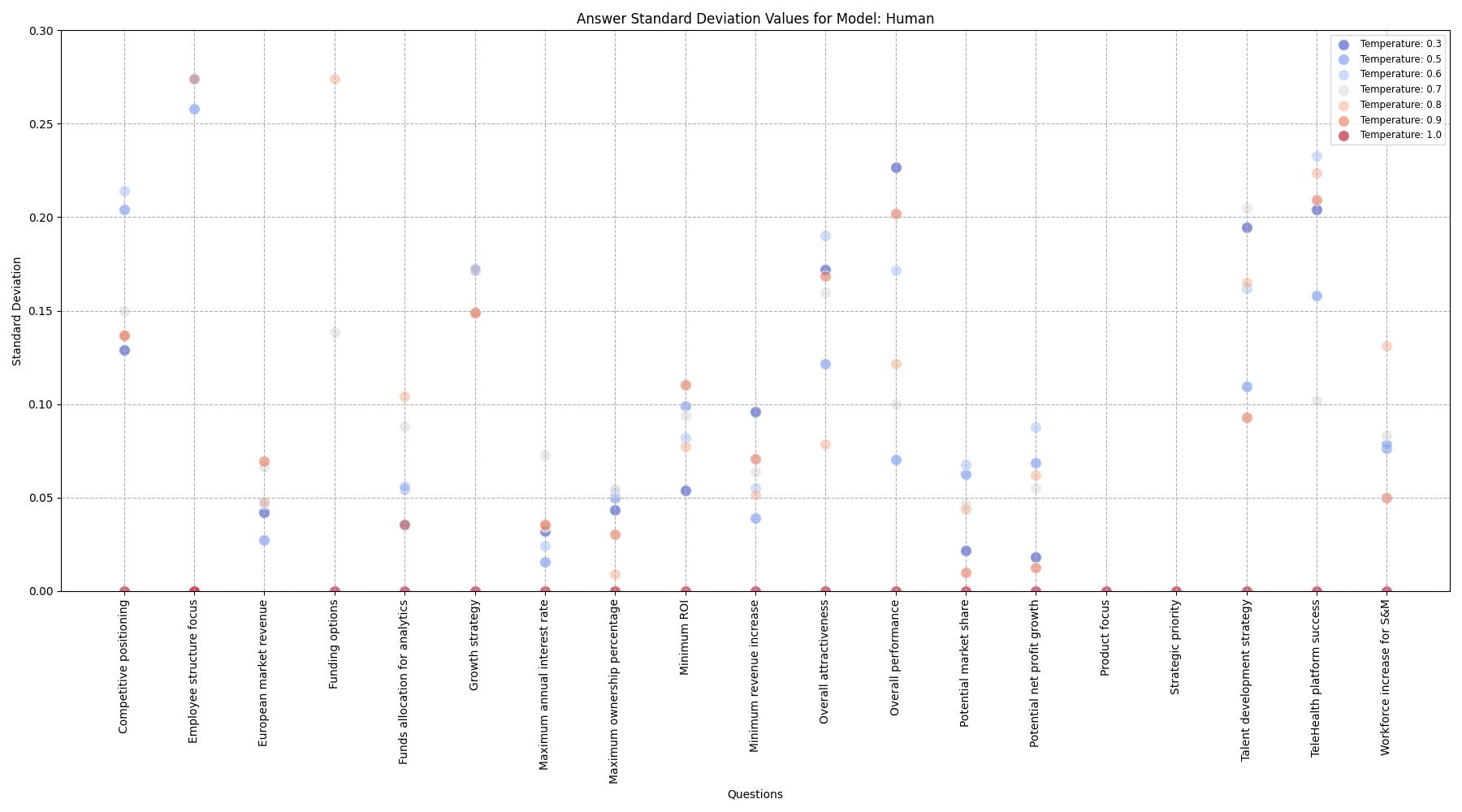
Comparing the standard deviation of responses for humans, GPT-4, and GPT-3.5, we find that humans have a higher average standard deviation (16.4%) than LLMs (GPT-4: 4.1%, GPT-3.5: 5.5%).
I then created a line chart showing the average noise by temperature for LLMs. Note that the self-assessed power level was used as the "temperature" for people. This is obviously not comparable, but it's the only way I could think of to compare LLMs to humans in a table. That is where you can clearly see the dynamics of the LLMs noise levels, as well as average noise values for human participants.

Conclusions
In the end, then, we see that both the GPT-3.5 and GPT-4 Large Language Models have lower noise compared to human decision makers in the EMBA program (4.1% and 5.5%, respectively, for LLMs versus 16.4% on average for humans). (Direct comparison of LLM noise results to human noise is difficult because we're comparing ensemble probability (for humans) to time probability (for LLMs). This only gives a directional estimate. A more accurate comparison would be possible if we received the answers to the same question multiple times from the same person without recollection). The noise in the LLMs increases with higher temperature settings, consistent with the hypothesis that higher temperatures introduce more randomness into the model's results. However, despite this increase, the noise in the LLMs remained lower than in the human participants.
The similarity in performance between GPT-4 and GPT-3.5 suggests that the improvements in the architecture of GPT-4 over its predecessor didn't result in a significant reduction in noise. It's important to note that while LLMs have lower noise levels than human participants, this doesn't necessarily mean that they always make better or more accurate decisions. LLMs still rely on the information they have been trained on, which isn't always applicable to the specific context of a given problem.
The key takeaway from this experiment is that, at least from a decision noise perspective, the LLMs tested are pretty good on their own and compared to humans. This brings them one step closer to becoming effective decision-makers under uncertainty.
Business Implications
Everyone is talking about applications of AI in our daily lives and in business. Research like this consistently shows that AI's thinking and decision-making capabilities are growing and, in some cases (like this one), surpassing those of humans. This means that these systems will inevitably find their way into daily business processes, not only to automate daily work, but also to make management decisions.
However, there are still many serious problems to be solved before this can happen, the most important of which I consider to be:
Hallucinations. LLMs can confidently make mistakes - they still tend to hallucinate and give confident but wrong answers when they don't know certain things.
Size of context. The best decisions take into account a large context of diverse information. Much of this context is difficult to verbalize (e.g., the body language of a business partner at a recent meeting). And for the information that can be verbalized, the "information window" for LLMs is limited by the maximum number of tokens that can be shared there.
Lack of accountability. As AI agents become more involved in enterprise decision making, it can become more difficult to assign responsibility when mistakes occur, complicating liability issues.
Bias and discrimination: AI agents may unintentionally perpetuate existing biases in training data, leading to unfair or discriminatory decisions.
At this point, however, the future seems inevitable - AI agents will be used for decision-making tasks with increasing frequency and quality.
Future Research Directions
Although this study provides a solid foundation for understanding noise levels in LLMs, further research is needed to extend these findings. Future studies could investigate the following aspects:
The effects of domain-specific fine-tuning on noise reduction in LLMs.
Investigate possible correlations between question types and noise levels in LLMs and whether certain question types are more susceptible to noise.
The relationship between LLMs' confidence in their responses and the actual noise level in those responses.
The use of ensemble approaches to combine the results of multiple LLMs to reduce noise and improve decision accuracy.
By further exploring the capabilities and limitations of LLMs in decision making, researchers can continue to improve the practical applications of these powerful AI systems and unlock their potential to revolutionize industries and improve human decision making.
Resources
Raw answers from the LLM and students, along with the code used for execution and analysis of this study can be found on GitHub.